
Umi-OCR 是一款免费开源的离线文字识别软件,支持多语言和批量识别图片、PDF,能去除水印并识别或生成二维码。它适用于文档数字化、截图文字提取、自动化数据录入等场景。支持 Windows 和 Linux 系统,并提供命令行和 HTTP 接口,方便集成和自动化使用。
Umi-OCR 使用教程
Tip
视频教程请移步 YouTube 观看《Umi-OCR 使用教程》。
下载
Umi-OCR 下载安装
- Windows
- Linux
解压软件包,无需安装,直接双击 Umi-OCR.exe 启动。
Linux 用户可运行 umi-ocr.sh 脚本启动。
解压软件包,无需安装,直接双击 Umi-OCR.exe 启动。
Linux 用户可运行 umi-ocr.sh 脚本启动。
使用说明
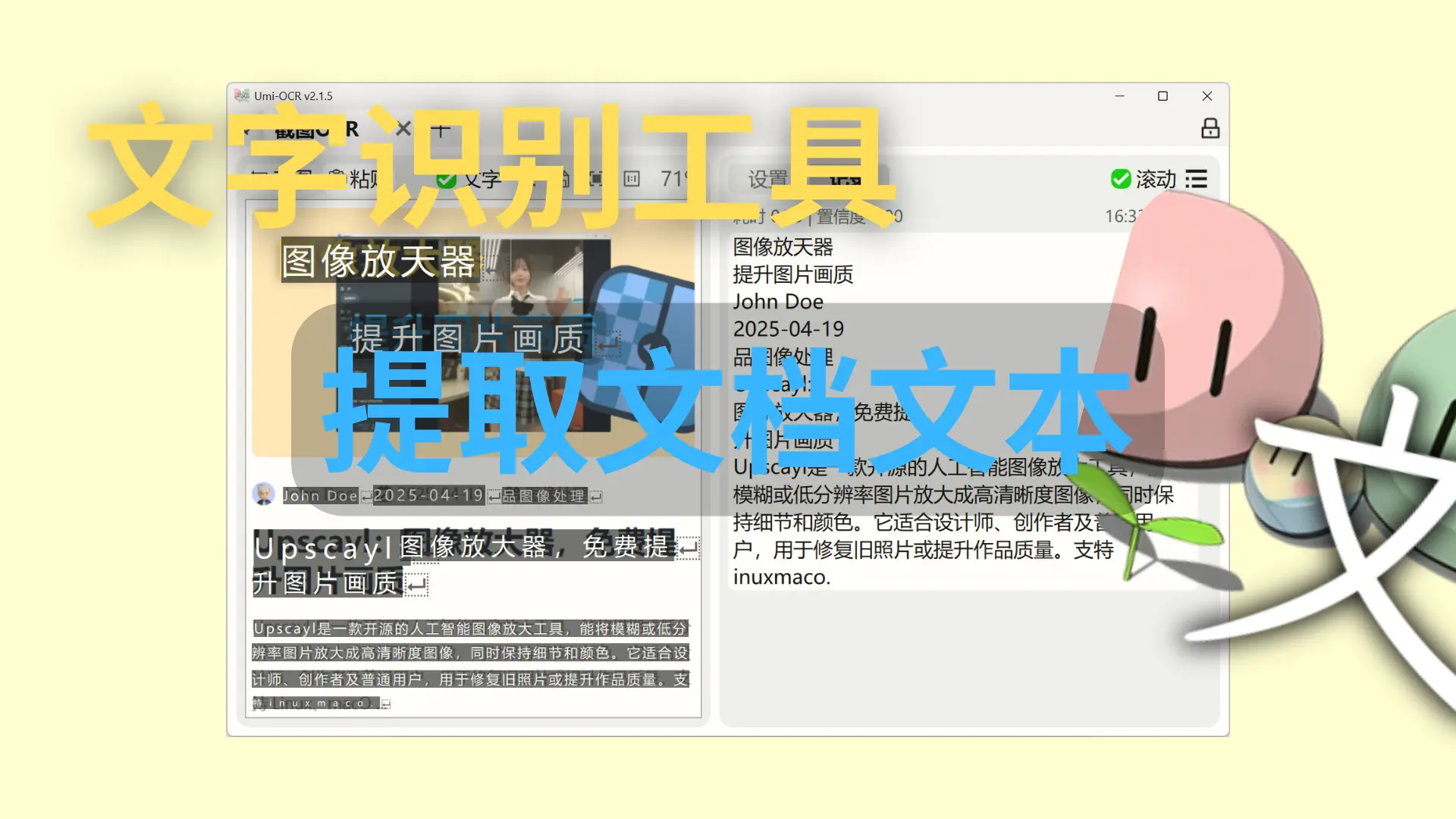
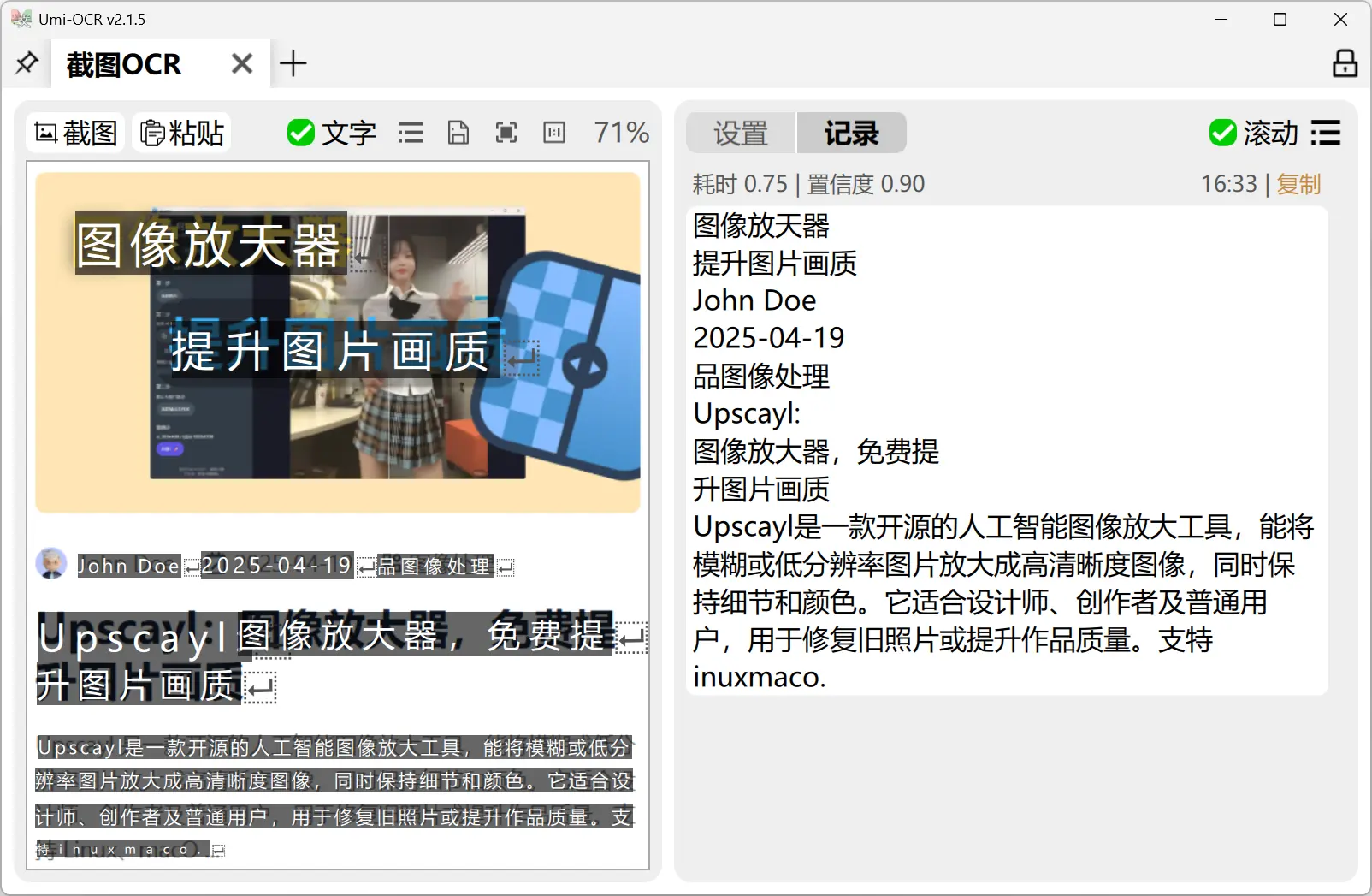
截图 OCR
- 通过快捷键或界面按钮,快速截图识别图片中的文字
- 支持复制、编辑识别结果,支持多条识别历史记录管理
- 可粘贴图片到软件窗口直接识别
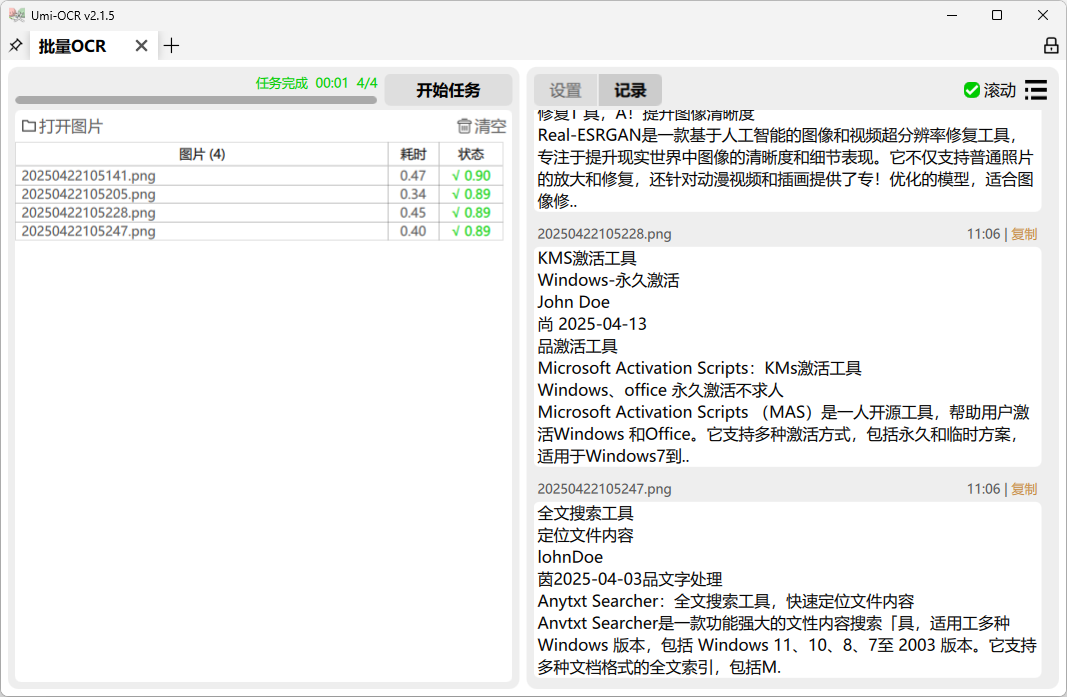
批量 OCR
- 支持批量导入本地图片(jpg、png、webp 等格式),一次性识别大量文件
- 识别结果可导出为 txt、csv、jsonl、md 等格式
- 支持“忽略区域”设置,排除水印、LOGO 等干扰内容
文档识别
- 支持 PDF、xps、epub、mobi 等格式文档的 OCR 识别
- 可输出为双层可搜索 PDF,便于后续检索
- 支持设置忽略区域,自动关机/休眠等任务选项
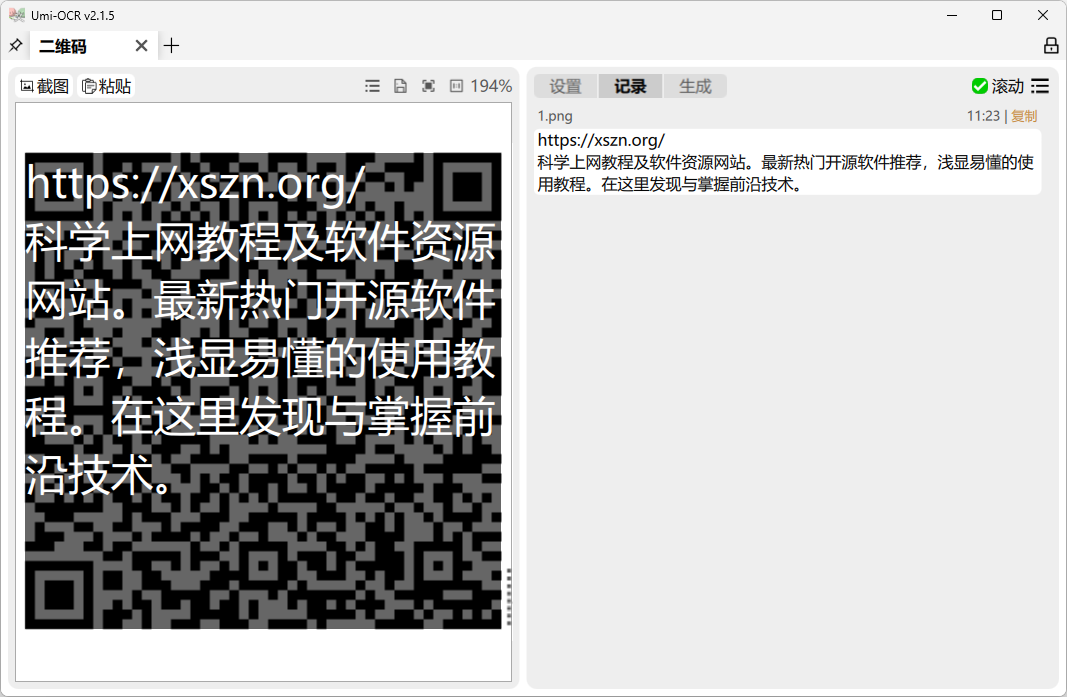
二维码功能
- 支持识别图片中的二维码、条形码(19 种协议)
- 支持输入文本生成二维码图片,支持纠错等级设置
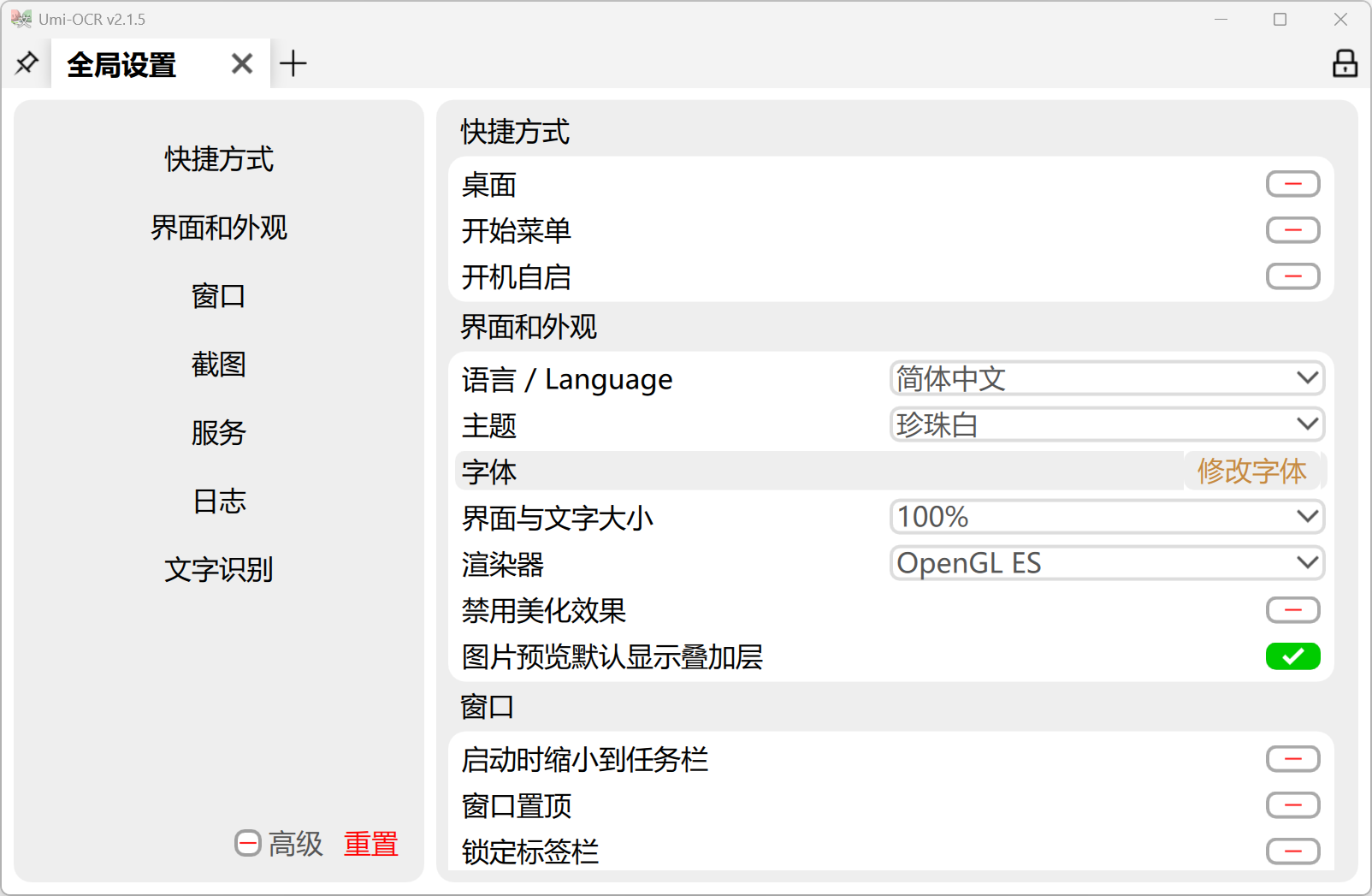
全局设置与高级用法
- 支持多语言界面、主题切换、快捷方式添加、开机自启等
- 支持命令行和 HTTP 接口,便于开发者二次集成和自动化调用
- 可切换不同 OCR 引擎插件,满足不同性能和兼容性需求
Umi-OCR 功能丰富,支持截图、批量、文档和二维码等文字识别,操作简单,适合高效提取和管理文本。首次运行如遇报错,可按提示解决。建议关注官方更新,不要同时安装不同引擎版本,软件永久免费,欢迎参与社区反馈和翻译。
参考资料
Note
软件资源分享 by 行书指南 is licensed under CC BY-NC-ND 4.0